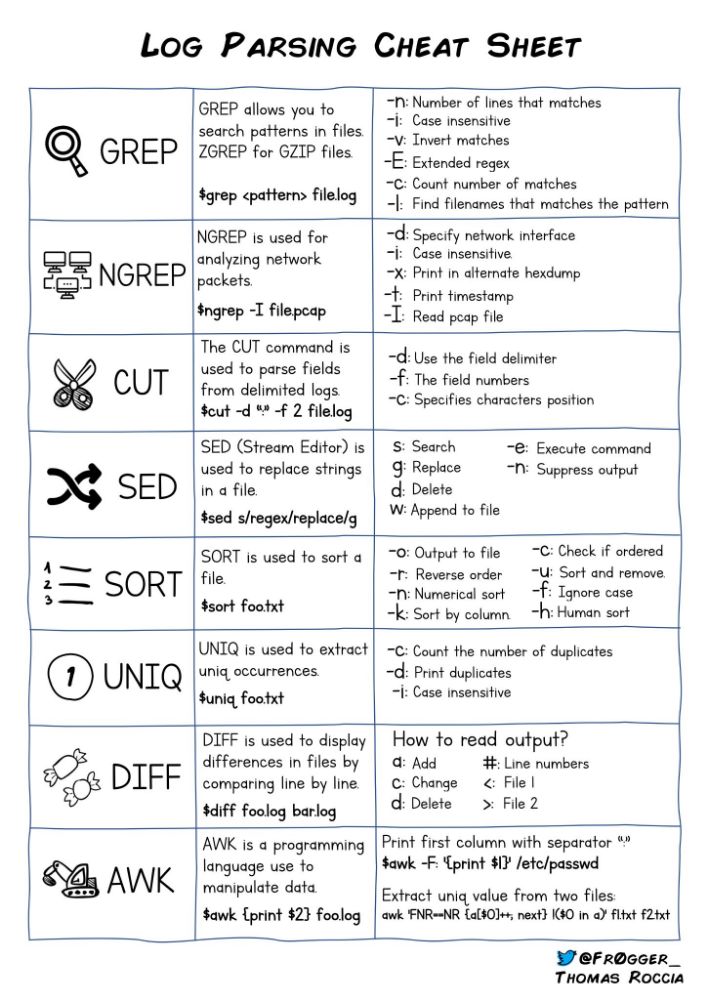
لینوکس ابزارهای text processing متنوع و با بازدهی بالایی مثل awk و sed و cut و sort و انواع grep و … دارد که حتی هنوز هم در کارهای بسیار کوچک تا بسیار بزرگ پراستفاده هستند.
شما ممکنه روزانه میلیون ها خط لاگ یا اطلاعات دیگر داشته باشید که به هر دلیل ریختن آن ها در یک پایگاه داده و کوئری گرفتن از آن میسر یا بهینه نیست یا بصرفه نیست برای پیدا کردن یک اطلاعات مشخص از انبوهی از داده های موقت یک پایگاه داده بالا بیاورید و دردسرهای آن را تحمل کنید یا اصلاً ممکنه تمایل داشته باشید خروجی اطلاعات مستقیماً به دستور دیگری فرستاده شود (پایپ | بشه) یا ممکنه تمایل داشته باشید اطلاعات را با فرمت و دامنه مشخص و فیلتر شده به دیتابیس بریزید یا … . بجز اینکه در انواع shell scripting و automation فراوان به این دستورات و ابزارها نیاز دارید.
یکی از معروفترین و پرکاربردترین و البته قوی ترین این ابزارها دستور awk (آوک) است که نام آن از مخفف اول نام فامیل Alfred Aho, Peter Weinberger, Brian Kernighan که نویسندگان نسخه اولیه در 1977 گرفته شده.

آوک یک ابزار اسکریپت نویسی مبتنی بر manipulating columns of data است، یعنی مثل spreadsheet با سطر و ستون در یک فایل یا مقدار ورودی text کار دارید.
خلاصه قضیه به اینصورت است :
محتوی تکست براساس فاصله ستون بندی می شود و براساس n\ سطر بندی.
بصورت پیش فرض awk ستون ها را با فاصله از هم جدا تشخیص می دهد اما می توان این را تغییر داد، مثلاً در فایل های CSV که ستون ها با , مشخص شده می توان با سوییچ F- جداکننده ستون ها را مشخص کرد.
عبارت 1$ در awk یعنی ستون 1 و همینطور 2$ یعنی ستون 2 و … ، ستون آخر با NF$ به معنای number of fields مشخص می شود و 0$ یعنی همش. (از یک می شمرد.)
شما می توانید patterns و actions تعریف کنید و در آن ها از انواع تابع و شرط و حلقه و … استفاده بنمایید، این مجموعه یک rule می شود. actionها را داخل {} می نویسند. می توان در یک اسکریپت چند اکشن با استفاده از چند {} داشت. کل rule نیز باید در ' ' باشد.
مثل یک زبان برنامه نویسی بسیار مشابه C اما با ادبیات و شیوه خودش توابع و متغییرها و شرط ها و حلقه ها و آرایه و … را دارد و بعضاً برنامه های قوی برای پردازش متن بخصوص از جنس لاگ با آوک نوشته شده است.
وقتی مثلاً یک فایل text را می خوانید اسکریپت awk خط به خط اجرا و اعمال می شود، مثل یک حلقه foreach به ازای هر خط.
همچنین اگر بخواهیم متنی را به محتوی پردازش شده اضافه کنیم داخل " " می نویسیم.
ساختار کلی دستور به اینصورت است :
$ awk options '{program}' file /* کل برنامه داخل '' است و یک فایل برای پردازش به آن داده می شود*/
مثلاً
$awk '{print $1}' textFile /*پرینت ستون اول از فایل*/
یا
$date | awk '{print $2,$3,$6}' /*date خروجی فقط ماه و روز و سال از دستور */
راهنمای کاملش را می توانید از لینک زیر ببینید و البته خیلی مفصل است و خیلی کارها می شه باهاش کرد. من خیلی خلاصه پرکاربردترین مبانی را برای معرفی خدمتتان عرض می کنم :
به مثال تصویر ذیل دقت بفرمایید :
یک فایل تکست با نام awk_text با محتوی مشخص در تصویر ساخته ام، به تصویر دقت بفرمایید :
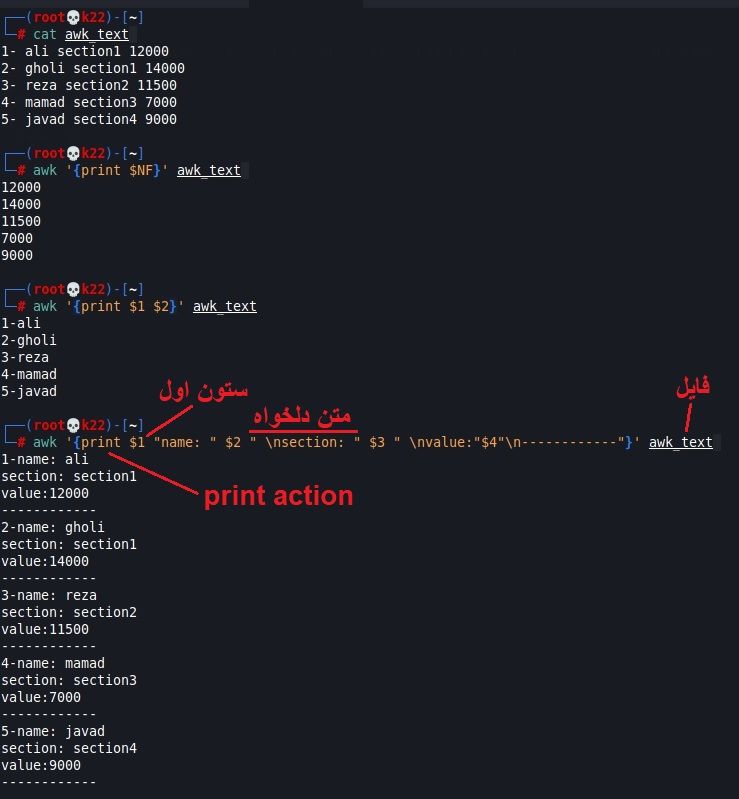
اگر به مثال بالا دقت بفرمایید تا حدود زیادی ساختار awk را بدست خواهید آورد و اکنون سراغ نکته ها و مثال های تمرینی می رویم.
به یک مثال از مقداردهی و manipulating یک رشته توجه بفرمایید :
echo "Hello Mahdi" | awk '{$2="Reza"; print $0}'
یا به یک مقایسه عددی توجه بفرمایید :
awk '{if ($4 > 10000) print $2}' awk.txt
برای تغییر جداکننده ستون ها از پیش فرض space گفتیم می توان از سوییچ F- استفاده کرد. مثلاً:
$awk -F "," '{print $1}' csv_file.csv
یا
$awk -F ":" '{print $1}' /etc/passwd
" " یا بدون
$awk -F: '{print $1}' /etc/passwd
می توان با استفاده از چند {} چند action تعریف کرد. مثلاً :
echo "hello ali" | awk '{$2="Mahdi"; print $0}{$1="salam"; print $0}'
Hello Mahdi
salam Mahdi
یکسری Built-in Variables دارد که چند تا مثال ازشون میزنیم ، از جمله :
FIELDWIDTHS Specifies the field width.
RS Specifies the record separator.
FS Specifies the field separator.
OFS Specifies the Output separator.
ORS Specifies the Output separator.
ARGC Retrieves the number of passed parameters.
ARGV Retrieves the command line parameters.
ENVIRON Array of the shell environment variables and corresponding values.
FILENAME The file name that is processed by awk.
NF Fields count of the line being processed.
NR Retrieves total count of processed records.
FNR The record which is processed.
IGNORECASE To ignore the character case.
مثلاً :
cat /etc/passwd | awk 'NR==1,NR==4 {print $0}'
یعنی خط شماره 1 تا 4 را چاپ کن. کمی ادبیات و تکنیک های غریبی داشته و استفاده از توابع و متغییرها و شرط ها در awk نیاز به تمرین و مثال دارد.
دقت بفرمایید وقتی متغییر را قبل از action استفاده می کنیم در حقیقت آن را مقداردهی می کنیم و در داخل action مقدار آن را می خوانیم.
یک نکته جالب هم اینه که می توانید چند فایل را برای پردازش همزمان بهش بدهید. مثلاً من اینجا 2 فایل را دادم که مجموع خطوطشان را نمایش بدهد :
awk 'END {print "Number of Lines : "NR}' awk.txt /etc/passwd
Number of Lines: 67
همچنین می توانید Preprocessing و Postprocessing تعریف کنید، یعنی قبل و بعد از اجرای اسکریپت یک دستوری اجرا شود. با BEGIN و END ، مثلاً :
awk 'BEGIN{print "The File Contents:\n--------"} {print $0} END{print "--------\n" NR" Rows Processed"}' awk_text
The File Contents:
----
1. mammad section1 1000
2. reza section2 2500
3. ali section3 400
4. hossein section4 700
5. Mahdi section5 5000
----
5 Rows Processed
از BEGIN برای مقداردهی های اولیه هم استفاده می کنیم، مثلاً :
awk 'BEGIN{FS=":" OFS="-"} {print $1,$6,$7}' /etc/passwd
اینجا تعریف کردیم فایل را که می خوانی جدا کننده : است و وقتی چاپ می کنی جداکننده - باشد.
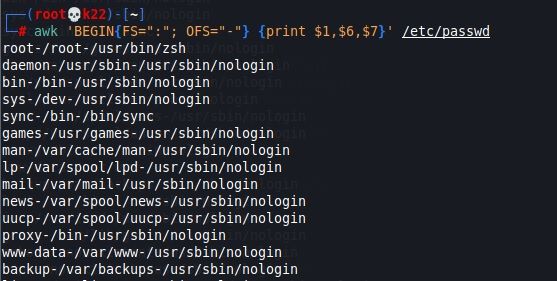
به استفاده از ; برای جدا کردن متغییرها داخل یک action و نوشتن کل قضیه در یک ' ' توجه بفرمایید.
یا مثال چاپ تعداد خط در یک فایل با NR :
awk 'END {print "Number of Lines : "NR}' awk_text
یک مثال دیگر با حلقه for و آرگومان :
awk 'BEGIN {
for (i = 0; i < ARGC - 1; ++i) {
printf "ARGV[%d] = %s\n", i, ARGV[i]
}
}' one two three four
ARGV[0] = awk
ARGV[1] = one
ARGV[2] = two
ARGV[3] = three
همانطور که ملاحظه می فرمایید استفاده از شرط ها و حلقه ها را هم پشتیبانی می کند.یک مثال دیگر از
حلقه for برای شمارش :
awk 'BEGIN {for(i=1;i<=10;i++) print i"*"i"="i*i;}'
1*1=1
2*2=4
3*3=9
4*4=16
5*5=25
6*6=36
7*7=49
8*8=64
9*9=81
10*10=100
یک مثال برای چاپ کاربر جاری با استفاده از کلید USER در ENVIRON (متغییرهای محیطی لینوکس) :
awk 'BEGIN { print ENVIRON["USER"] }' /* print current user*/
یا گرفتن لیست یک پروسس خاص از ps :
ps -ef | awk '{if($NF=="zsh") print $0}'
یعنی در مثال بالا گفته ام اگر در ps -ef آخرین ستون zsh بود آن را چاپ کن.
با همان قوانین regex در ابتدای action می توانید بین / / یک regex تعریف کنید. به مثال دقت بفرمایید :
awk '/section1/ {print $2 "\t" $4}' awk_text
یکم مثال قوی تر، در اینجا لیست shellهای موجود روی سیستم را تمیز گرفته ایم :
awk -F "/" '/^\// {print $NF}' /etc/shells | uniq | sort
bash
dash
rbash
sh
tmux
zsh
یکسری هم توابع پیش فرض در awk برای استفاده هستند، حتی خودتان هم می توانید function تعریف کنید، awk عملاً یک زبان برنامه نویسی پردازش متنی ستونی است. مثل :
Mathematical functions:
atan2(y, x)
cos(expr)
exp(expr)
int(expr)
log(expr)
rand
sin(expr)
sqrt(expr)
srand([expr])
String functions:
asort(arr [, d [, how] ])
asorti(arr [, d [, how] ])
gsub(regex, sub, string)
index(str, sub)
length(str)
match(str, regex)
split(str, arr, regex)
sprintf(format, expr-list)
strtonum(str)
sub(regex, sub, string)
substr(str, start, l)
tolower(str)
toupper(str)
Time functions:
systime
mktime(datespec)
strftime([format [, timestamp[, utc-flag]]])
مثلا:
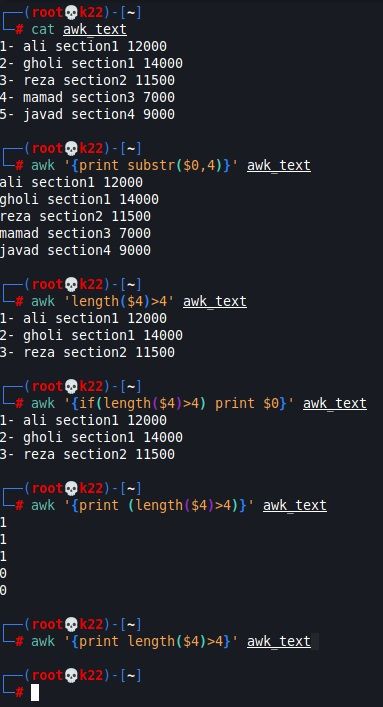
در مثال بالا مورد تابع length چند مثال زده ام که شیوه صحیح استفاده از شرط و تابع را مرور کنیم.
یک مثال از تابع match، می خواهم ایندکس کاراکتر a در هر خط را پیدا کنم :
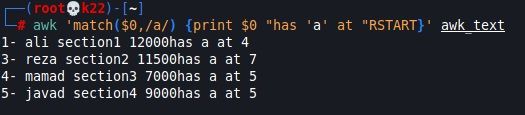
دقت بفرمایید از 1 می شمرد و RSTART هم از همان متغییرهای پیش فرض awk و به معنای matchThe first occurrence position of function matching است.
یعنی برای هر خط ابتدا match اجرا می شود و اگر کاراکتر a در آن خط بود طبق تعریف RSTART را مقداردهی می کند.
زمانی که اسکریپت شما پیچیده و با چند شرط و تابع و … باشد دیگر نمی توانید و راحت نیست در خط فرمان همه را تایپ کنید. بنابراین می توانید در یک فایل بصورت تکست بنویسید با پسوند ترجیحاً awk ذخیره کنید و با سوییچ f برای اجرا به awk بدهید.
awk -f command.awk awk_text
حالا یک روش دیگر این هم این است که در لینوکس به یک اسکریپت اجرایی تبدیلش کنید. در مثال ذیل این اسکریپت را در فایل accountcounter.awk نوشته ام و سپس به آن با chmod +x مجوز اجرا داده ام و بعد اجرا کرده ام.
#!/usr/bin/awk -f
BEGIN {
# set the input and output field separators
FS=":"
# zero the accounts counter
accounts=0
}
{
# count another account
accounts++
}
END {
# print the results
print accounts " accounts."
}
chmod 755 account.awk && ./acount.awk /etc/passwd
62 accounts.
در مثال بالا دقت بفرمایید که awk در حقیقت بصورت یک حلقه به ازای هر خط اجرا می شود.
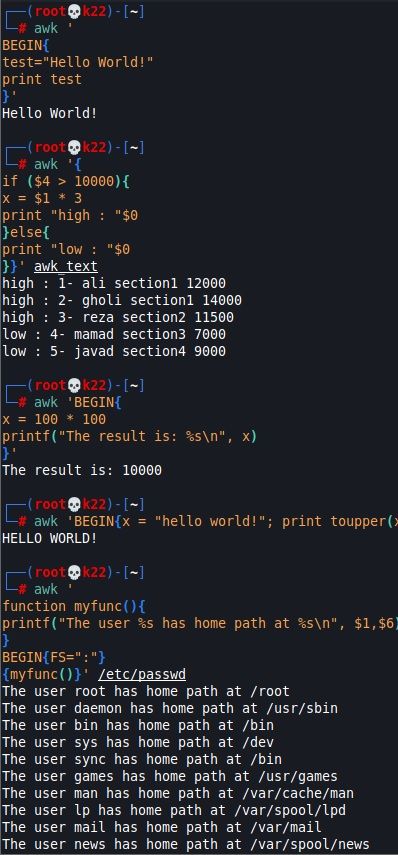
چند مثال در تصویر با همان فایل awk_text که در ابتدا ساختیم زده ام :
من در این مقاله بسیار مختصر و با چند مثال کاربرد awk و ادبیات کلی آن را نشان دادم، در حقیقت معمولاً همینقدر برای کارهای من کفایت می کند و چیز اضافه تری هم نیاز باشد موردی جستجو می کنم، اما اگر خیلی با پردازش raw data تکست ستونی و سطری سر و کار دارید احتمالاً از وقتی که برای یادگیری عمیق تر awk بگذارید پشیمان نخواهید شد. اصلاً ما یک مهارت پیشرفته لینوکسی داریم Master in AWK!