ردیس (Redis) چیست؟
ردیس(Redis) که نام آن برگرفته از عبارت (Remote Dictionary server) است درواقع یک پایگاه داده بر پایه NOSQL و مبتنی بر حالت Key/Value می باشد که داده ها را در حافظه RAM نگهداری میکند.
ویژگیهایی نظیر سادگی، کارایی استثنایی و خاصیت atomic در ویرایش دادهها در Redis باعث میشود که حل کردن مسائلی که در دیتابیسهای متداول رابطهای نظیر MySQL مشکل بود، در Redis به راحتی انجام شود.
تفاوت Redis با دیگر پایگاه دادهها چیست؟
ردیس با پایگاه دادههایی مثل MySQL وOracle کاملاً متفاوت است؛ چرا که در آن خبری از ستونها، ردیفها، table ها، توابع و … نیست. همچنین ردیس از دستورات Select، Insert، Updat، Delete و … نیز استفاده نمیکند.
در عوض، ردیس از ساختمان دادههایی مثل String، Lists ،Sets ،Hashes و … برای مرتب کردن اطلاعات استفاده میکند.
استفادههای متداول :
Caching
به دلیل کارایی بالای Redis در این که حجم و سرعت خواندن و نوشتن در Redis از دیتابیسهای رابطهای بسیار بالاتر و بیشتر است، اکثر توسعه دهندگان سراغ Redis میروند.
با توجه به قابلیتهای Redis در اینکه میتوان تمام دادهها را بر روی دیسکها ذخیره کرد (redis persistence)، جایگزین memcached در کشکردن نیز است. در ادامه مقاله به ماندگاری داده ها در Redis اشاره میکنیم.
Publish and Subscribe
بعد از نسخه 2.0، Redis قابلیتی تحت عنوان الگوی پیامرسانی Public/Subscribe معرفی کرد که برای توزیع دادهها استفاده میشود.
برخی از سازمانها به دلیل سادگی و کارایی بالای Redis، از سایر سیستمهای توزیع پیام نظیر RabbitMQ و Zeromq به Redis مهاجرت کردند.
Queues
پروژههایی نظیر Resque از Redis برای ایجاد صف background job استفاده میکنند.
Counters
دستورات atomic مانند HINCRBY، اجازه پیادهسازی ساده و به صرفه شمارندهها را میدهند. ایجاد یک شمارنده به سادگی تعیین یک نام برای کلید و یا فیلد و اجرای دستور HINCRBY است. هیچ نیازی به خواندن دیتا قبل از افزایش شمارنده و در واقع طرح و اساسی برای بروزرسانی آن نیست. از آنجایی که این نوع دستورات، دستورات atomic هستند، شمارندهها پایداری خود را به هنگامی که توسط چندین سرور تغییر مییابند، حفظ میکنند. براي نمونه شما ميتونيد براي process bar و سیستم لودینگ از این قابلیت استفاده نمایید.
ردیس از چه ساختمان داده ها و Data type هایی پشتیبانی میکنه؟
ردیس یک دیتابیس key/value است اما این مقدار قرار نیست همیشه یک رشته string باشد ردیس از پنج نوع داده پشتیبانی می کند:
Strings: رشته ها میتوانند هر نوع داده ای باشند یک رشته حداکثر از 512 مگابایت پشتیبانی می کند.
Lists: لیست ها در واقع مجموعه ای از رشته ها هستند که به ترتیب درج مرتب شده اند میتوان به اول یا انتهای لیست یک عنصر جدید اضافه کرد.
Sets: مجموعه در واقع کلکسیون بدون ترتیب از رشته ها هستند میتوان در یک مجموعه رشته جدید اضافه یا حذف یا جستجو کرد.
Sorted Sets: همانند مجموعه است با این تفاوت که به هر عنصر مجموعه مرتب یک امتیاز تخصیص می یابد.
Hashes: هَش در واقع نگاشتی بین کلید و مقدار است و یک رشته جدید بین آن ها قرار می دهد که برای دسترسی به مقدار نیاز به کلید و هش به صورت همزمان است.
دستورات پرکاربرد در Redis:
تنظیم یک مقدار به صورت پیش فرض:
SET <key> <value>
SET firstname Mahdi
بازیابی یک مقدار
GET <key>
GET firstname
بررسی وجود یک کلید
EXISTS <key>
حذف یک کلید
یک کلید میتواند همراه با حافظه مربوطه، به صورت زیر حذف شود.
DEL <key>
این یک عملیات blocking همگام است.
روشی بهتر برای حذف کلیدها، لغو ارتباط آنها است، که حافظه مربوط به آنها میتواند بعدا جمعآوری شود.
UNLINK <key>
تعیین تاریخ انقضا برای یک کلید
EXPIRE <key> <seconds>
PEXPIRE <key> <milliseconds>
تنظیم یک کلید، بررسی وجود آن و تاریخ انقضا به طور همزمان
SET <key> <value> <EX seconds>|<PX milliseconds> NX|NX
NX - فقط وقتی که یک کلید وجود ندارد، تنظیم کن.
XX - فقط وقتی که یک کلید از قبل وجود دارد، تنظیم کن.
EX - زمان انقضا را برای کلید بر حسب ثانیه تعیین میکند.
PX - زمان انقضا را برای کلید بر حسب میلی ثانیه تعیین میکند.
SET firstname Mahdi EX 10 NX
این دستور، کلید firstname را با زمان انقاضی 10 ثانیه، فقط وقتی که کلید مورد نظر وجود ندارد، مساوی با مقدار «Mahdi» قرار میدهد.
تمام دستورات اشاره شده در بالا فقط برای ذخیرهسازی و دستکاری رشتهها و مقادیر integer بودند. ساختارهای داده دیگری مانند hashها، setها، آرایههای bit و… نیز وجود دارند، که میتوانند برای حل مشکلات پیچیده استفاده شوند.
Redis و MongoDB:
تفاوت این دو در این است که یکی به صورت دیتابیسی در حافظه، دیگری دیتابیسی بر روی دیسک است و هر کدام برای هدف خاصی طراحی شدهاند اما اغلب در کنار هم با هدف افزایش سرعت پردازش و کارایی دیتابیسهای NoSQL استفاده میشوند. به دلیل قابلیت cache که در Redis وجود دارد، خیلی سریعتر میتوان به دادهها دسترسی پیدا کرد. در نتیجه میتوانیم از این قابلیت بهره ببریم و Redis را به عنوان رابطی برای MongoDB استفاده کنیم تا بتوانیم سریعتر و موثرتر دادههای بیشتر و بزرگتری را real-time تر بروزرسانی و ویرایش کنیم. به دلیل این که MongoDB میتواند حجم قابل توجهی از دادهها را ذخیره کند و از طرف دیگر با توجه به سرعت بسیار بالای Redis در پردازش آنها، استفاده از این دو درکنار یکدیگر میتواند راه حلی برای مسائل مختلفی که در آنها سرعت و کارایی حرف اول را میزند، باشد.
ترکیب ساختار دادههای سطح بالا، عملکرد وصف نشدنی و بسیار عالی Redis و سایر مسایلی که مطرح کردیم باعث میشود که Redis نقش آچار فرانسه در ذخیرهسازی دادهها را برای توسعهدهندگان داشته باشد.
Redis برای حل چالشهایی که به هنگام ساخت سیستمهای بلادرنگ یا real-time، به دلیل برخورداری از عملیاتهایی که برای دیتاها در دیتابیس نیاز است، مناسب است.
Redis بیشتر کارایی و تمرکز خود را بر روی این میگذارد که دادهها در حافظه هستند. در عین حال دادههای Redis قابلیت ذخیرهسازی بر روی دیسک را نیز دارند، اما به این نکته توجه کنید که اگر تنظیمات Redis به صورت اشتباه انجام شود، موجب از دست دادن بخش بزرگی از دادهها، به هنگام خاموش کردن و یا پایین آمدن ناگهانی Redis میشود.
ماندگاری داده ها در Redis
پایگاه داده redis روش های متفاوتی برای ماندگاری داده فراهم میکند:
1- در روش RDB که مخفف Redis Database Backup است، در بازه های زمانی مشخص از داده ها یک نسخه پشتیبان تهیه می شود. به عنوان مثال می توان redis را به گونه ای پیکربندی کرد که هر 30 دقیقه از کل داده ها یک نسخه در دیسک ذخیره کند.
2- در روش AOF که مخفف Append Only file است، هر عملیات write که سرور دریافت میکند، در یک فایل لاگ می شود. درنتیجه در زمان شروع مجدد سرور، میتوان از آن کل داده را بازسازی کرد. دستورات به همان فرمت redis ذخیره می شوند. Redis این قابلیت را دارد که در صورت بزرگ شدن فایل، آن را Rewrite کند.
3- امکان غیرفعال کردن ماندگاری داده نیز وجود دارد
4- امکان استفاده از هر دو روش RDB و AOF وجود دارد. در این صورت هنگام شروع مجدد سرور، از فایل AOF برای بازسازی داده ها استفاده می شود.
مزایای RDB
1- RDB یک فایل جمع و جور است که داده های redis را نشان می دهد. درنتیجه برای پشتیبان گیری بسیار ایده آل است. برای مثال شما فایل های RDB را هر ساعت برای 24 ساعت گذشته آرشیو میکنید و به مدت 30 روز نگهداری میکنید. این به شما اجازه میدهد نسخه های مختلف از مجموعه داده را در مواقع disaster بازیابی کنید.
2- چون RDB فقط یک فایل است و درنتیجه میتواند به راحتی در شبکه جابجا شود و برای disaster recovery بسیار عالی است.
3- این روش از کارایی Redis را بیشینه می کند چون تنها کاری که پردازش مادر Redis برای این روش انجام می دهد، ایجاد یک child برای انجام این کار است.
4- در این روش بازیابی داده سریع تر از روش AOF است.
معایب RDB
1- با توجه به اینکه در این روش در بازه های زمانی نسخه شتیبان تهیه می شود امکان از دست رفتن برخی از داده ها وجود دارد.
2- در این روش از یک پردازش Chld استفاده می شود. درصورتی که حجم فایل بزرگ باشد fork می تواند زمانبر باش و درنتیجه Redis برای چند میلی ثانیه یا حتی یک ثانیه متوقف می شود.
مزایای AOF
1- این روش بسیار بادوام تر است. در این روش سیاست های مختلفی برای fsync میتوان انتخاب کرد: بدون sync، هر ثانیه، با هر کوئری. بصورت پیش فرض داده هر ثانیه sync می شود. در این صورت نهایتا داده یک ثانیه از دست می رود. روش هر ثانیه بسیار سریع است. اما روش fsync برای هر تغییر بسیار کند اما بسیار امن است.
2- در این روش در صورتی که فایل بزرگ شود بصورت خودکار Redis یک فایل جدید ایجاد می کند و نوشتن لاگ ها را در آن ادامه می دهد.
معایب AOF
1- حجم فایل های AOF نسبت به معادل RDB بزگتر است.
2- عموما AOF کندتر از RDB است و بستگی به سیاست انتخابی برای fsync دارد.
3- ممکن است باگ های نادری وجود داشته باشد که با استفاده از commandهای فایل AOF نتوان همه داده را بازیابی کرد. درصورتی که همچین باگی در RDB امکان پذیر نیست. اما ادعا می شود تا کنون چنین موردی گزارش نشده است.
تحلیل
برای رسیدن به اطمینان کامل لازم است از هر دو روش RDB و AOF استفاده شود. درصورتی که از دست چند دقیقه از داده ها برایتان اهمیت خاصی ندارد بهتر است از RDB استفاده کنید.
استفاده تنها از روش AOF توصیه نمی شود و بهتر است در بازه های زمانی حتما از RDB استفاده شود.
با توجه به اینکه در برنامه بلند مدت Redis ترکیب این دو روش و ارائه یک روش ترکیبی قرار دارد، توصیه ما استفاده از هر دو روش به صورت همزمان می باشد.
پیکربندی پیش فرض بصورت زیر است:
save 900 1
save 300 10
save 60 10000
هر 900 ثانیه اگر حداقل 1 کلید تغییر کند.
هر 300 ثانیه اگر حداقل 10 کلید تغییر کند.
هر 10000 ثانیه اگر حداقل 60 کلید تغییر کند.
پیکربندی ما برای AOF:
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
نصب Redis و RedisInsight با استفاده از داکر
از اونجایی که میخوایم Redis و RedisInsight رو با داکر نصب کنیم لازمه روی سیستممون داکر و داکر کامپوز نصب باشه؛ توی این مقاله گفتم چجوری میشه داکر و داکر کامپوز رو روی اوبونتو نصب کرد.
برای منابع سختافزاری هم، چون ردیس به صورت single-thread کار میکنه نیاز به coreهای زیاد CPU نداریم؛ رم هم لازم نیست سرعت خیلی زیادی داشته و حجمش هم بر اساس نیازتون و میزان دادهای که میخواید داخلش نگه دارید تعیین میشه؛ فقط نکته مهم اینه که نباید از swap استفاده کنید.
در کل ردیس خودش خیلی سبکه و بیشترین چیزی که میتونه روی پرفورمنسش اثر بذاره سرعت شبکه هستش؛ برای اطلاعات بیشتر در مورد سرعت و نکات پرفورمنسی میتونید به انتها مقاله یه نگاه بندازید.
ایجاد فایل کانفیگ Redis
ابتدا یه پوشه برای ردیسمون بسازیم:
mkdir -p /opt/redis/config
cd /opt/redis
حالا داخل پوشه config یه فایل کانفیگ با نام redis.conf بسازیم:
nano config/redis.conf
و محتویاتشو این قرار بدیم:
port 6379
requirepass my-redis-pass
maxmemory 1gb
maxmemory-policy allkeys-lru
save ""
با این کانفیگ، ردیس به عنوان کش روی پورت ۶۳۷۹ میتونه با پسورد ناامن my-redis-pass حداکثر از ۱ گیگ رم استفاده کنه و وقتی ۱ گیگ حافظه پر میشه با استفاده از الگوریتم LRU، اطلاعاتی که کمتر از بقیه استفاده شدن رو پاک کنه.
در صورتی که میخواید از ردیس به عنوان دیتابیس استفاده کنید (ینی اطلاعات روی دیسک ذخیره بشه) میتونید از این کانفیگ استفاده کنید:
port 6379
requirepass my-redis-pass
maxmemory 4gb
maxmemory-policy noeviction
save 3600 1
save 300 100
save 60 10000
# appendonly yes
dir /data/
میزان maxmemory رو برابر حداکثر مقدار دیتایی که میخواید نگه دارید (و البته میزان رم سیستمتون) قرار بدید.
سه خط saveای که نوشتیم به ترتیب به این معنیه که اطلاعاتو ذخیره کن رو دیسک اگه بعد از ۳۶۰۰ ثانیه ۱ کلید تغییر کنه یا بعد از ۳۰۰ ثانیه ۱۰۰ کلید تغییر کنه یا بعد از ۶۰ ثانیه ۱۰۰۰۰ کلید تغییر کنه؛ بر اساس نیازتون میتونید تغییرشون بدید.
با سیاستی که برای ذخیره روی دیسک نوشتیم، فرض کنید ظرف ۳۰ ثانیه ۵۰۰۰ کلید تغییر کنه و ردیس به صورت ناگهانی استاپ بشه (مثلا برق بره)؛ ۵۰۰۰تا تغییرمون هم از بین میره! اگر براتون قابل قبول نیست اون خط appendonly رو از کامنت دربیارید اینکار البته یه سری معایب دیگه داره که میتونید از لینک انتها مقاله اطلاعات کامل را دریافت نمایید
ایجاد پوشه و تنظیم دسترسی برای RedisInsight
با فرض اینکه هنوز داخل پوشه opt/redis هستیم، یه پوشه برای RedisInsight میسازیم و دسترسیشو تنظیم میکنیم:
mkdir -p insight/data
chown -R 1001 insight/data
ایجاد فایل docker-compose.yaml
version: "3.9"
services:
redis:
container_name: redis
image: redis:6.2
command: redis-server /usr/local/etc/redis/redis.conf
restart: unless-stopped
volumes:
- /opt/redis/data:/data
- /opt/redis/config:/usr/local/etc/redis
ports:
- "6379:6379"
redisinsight:
container_name: redisinsight
image: redislabs/redisinsight:1.11.1
restart: unless-stopped
volumes:
- /opt/redis/insight/data:/db
ports:
- "8001:8001"
اجرای کانتینرها
docker compose up -d
پس از دستور بالا داکر شروع میکنه ایمیجها رو دانلود میکنه و بعد از دانلود، کانتینرها رو اجرا میکنه و بعد از چند ثانیه اونها قابل استفاده خواهند بود.
الان ردیس روی پورت ۶۳۷۹ با پسورد my-redis-pass قابل استفاده خواهد بود؛
تنظیم RedisInsight
بعد از اینکه که کانتینرها رو اجرا کردید، اگه مشکل خاصی وجود نداشته باشه باید روی پورت ۸۰۰۱ سرورتون صفحه RedisInsight رو ببینید:
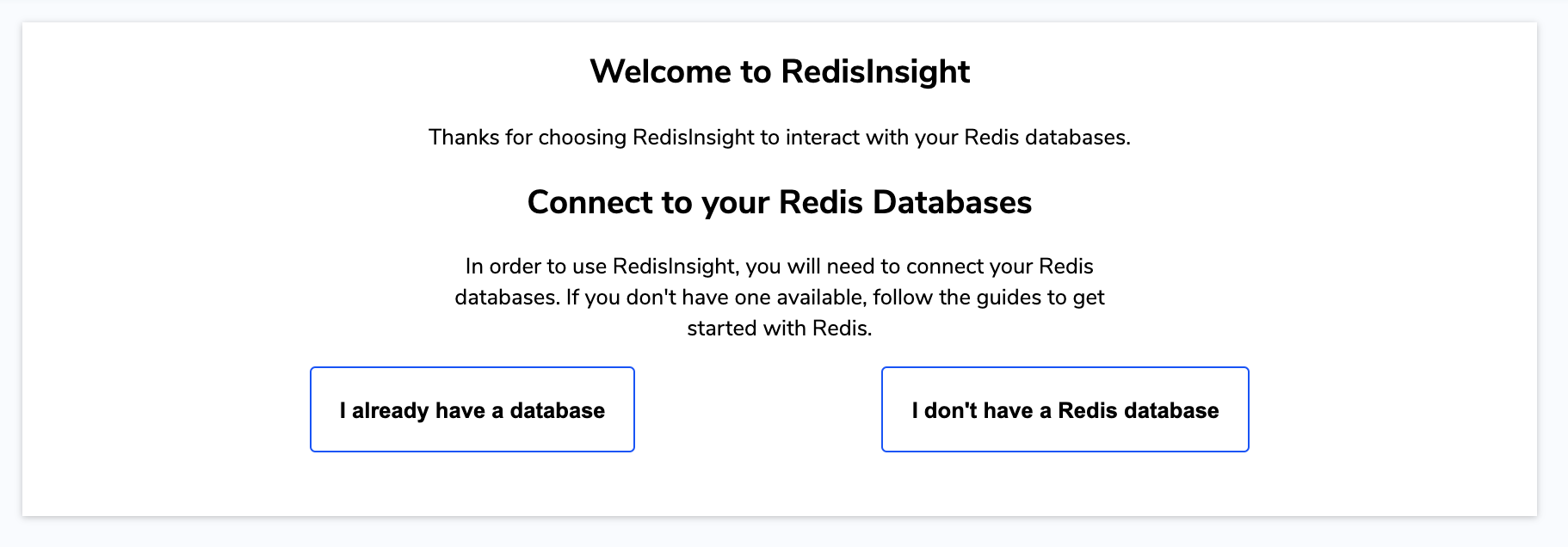 حالا روی “I already have a database” کلیک کنید و بعد هم گزینه “Connect to a Redis Database Using hostname and port” رو انتخاب کنید.
حالا روی “I already have a database” کلیک کنید و بعد هم گزینه “Connect to a Redis Database Using hostname and port” رو انتخاب کنید.
مشخصات ردیس رو به این شکل وارد کنید:
Host: redis
Port: 6379
Name: my-redis
Username: default
Password: my-redis-pass
حالا ردیسمون که اسمشو گذاشتیم my-redis به لیست دیتابیسها اضافه میشه و با کلیک روی اون بهش وصل میشیم و میتونیم از مانیتورینگ و سایر امکانات RedisInsight استفاده کنیم: